In the rapidly evolving world of artificial intelligence, efficiency and scalability are paramount. As AI systems, particularly large language models (LLMs), become the backbone of enterprise operations, innovations like the Mixture-of-Depths Attention (MoDA) model are changing the game. MoDA’s unique approach to leveraging both sequence and depth attention is paving the way for more effective and efficient AI architectures.
The Foundation: Transformer Architectures
Most modern LLMs build on the Transformer architecture, known for its self-attention mechanism that effectively handles token mixing. This architecture has been instrumental in enabling breakthroughs in AI, allowing models to process vast amounts of data with remarkable accuracy. The core concept involves projecting input tokens into queries, keys, and values, which then interact to determine the importance of different tokens in a sequence. A key limitation, however, has been the efficiency of depth scaling as models grow in size and complexity.
For instance, as models stack layers, they typically rely on depth residual connections, which can dilute important features due to repeated superposition. This has prompted the exploration of alternative mechanisms like Depth Dense and the innovative MoDA, which aim to optimize information propagation through depth streams.
Introducing Mixture-of-Depths Attention
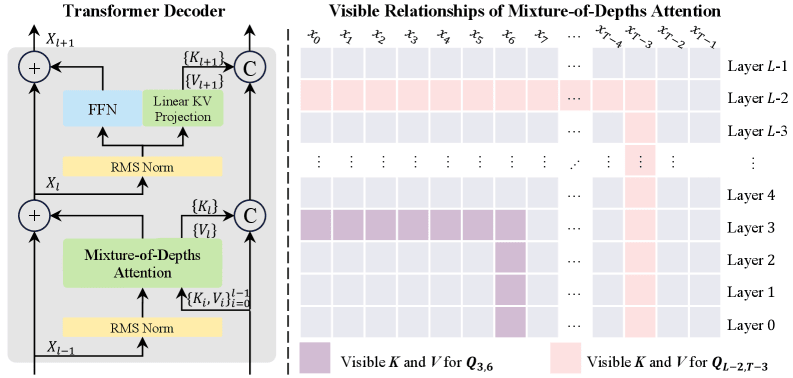
Mixture-of-Depths Attention (MoDA) represents a significant shift in how depth information is utilized within LLMs. Unlike traditional methods that separate sequence and depth processing, MoDA integrates these dimensions, allowing tokens to attend to both sequence-level and depth-level keys and values simultaneously. This unified approach provides a comprehensive representation space, enhancing model efficiency and performance.
MoDA leverages a single softmax operation to normalize attention scores across both dimensions, a feature that markedly reduces computational overhead. According to a review on liner.com (2026), this model not only improves perplexity but also aligns with industry trends towards more scalable AI architectures.

Efficiency and Scalability: A Detailed Look
The strength of MoDA lies in its ability to efficiently manage computational resources. Traditional depth-dense methods, while effective in preserving data integrity, incur high costs due to quadratic growth in computation with respect to depth. MoDA addresses this by reducing parameter complexity, which is particularly advantageous in settings where grouped query attention (GQA) is employed.
As highlighted in a Gartner prediction (2026), AI's impact on data analytics is set to grow, necessitating models that can scale effectively without prohibitive resource demands. MoDA’s design ensures that even as models scale, they remain computationally feasible and efficient.
Real-World Applications and Implications
MoDA's advancements have profound implications for industries relying on LLMs. By optimizing how models handle depth information, businesses can achieve faster, more accurate insights from their data. This is crucial in sectors like finance and healthcare, where real-time data processing can lead to significant competitive advantages.
For instance, in customer service automation, employing MoDA can enhance the capabilities of AI agents, making them more responsive and contextually aware. This aligns with the mission of Jina Code Systems, where we strive to build intelligent systems that enable businesses to innovate continuously.
The Future of AI with MoDA
Looking ahead, the adoption of MoDA is likely to accelerate as enterprises seek more efficient AI solutions. The model’s ability to balance complexity with performance makes it an attractive option for organizations aiming to leverage AI at scale. Furthermore, as AI continues to integrate deeper into organizational structures, models like MoDA will be essential in ensuring that technology not only keeps pace with business needs but also drives innovation.
At Jina Code Systems, we are committed to exploring and implementing such groundbreaking technologies, ensuring our clients remain at the forefront of the digital transformation landscape.
Conclusion
In conclusion, the Mixture-of-Depths Attention model represents a pivotal advancement in AI technology. By seamlessly integrating sequence and depth attention, MoDA offers a path forward for enterprises looking to maximize their AI capabilities efficiently. As the demand for scalable and effective AI solutions grows, partnering with experts like Jina Code Systems can ensure your organization is equipped to thrive in this dynamic landscape.

