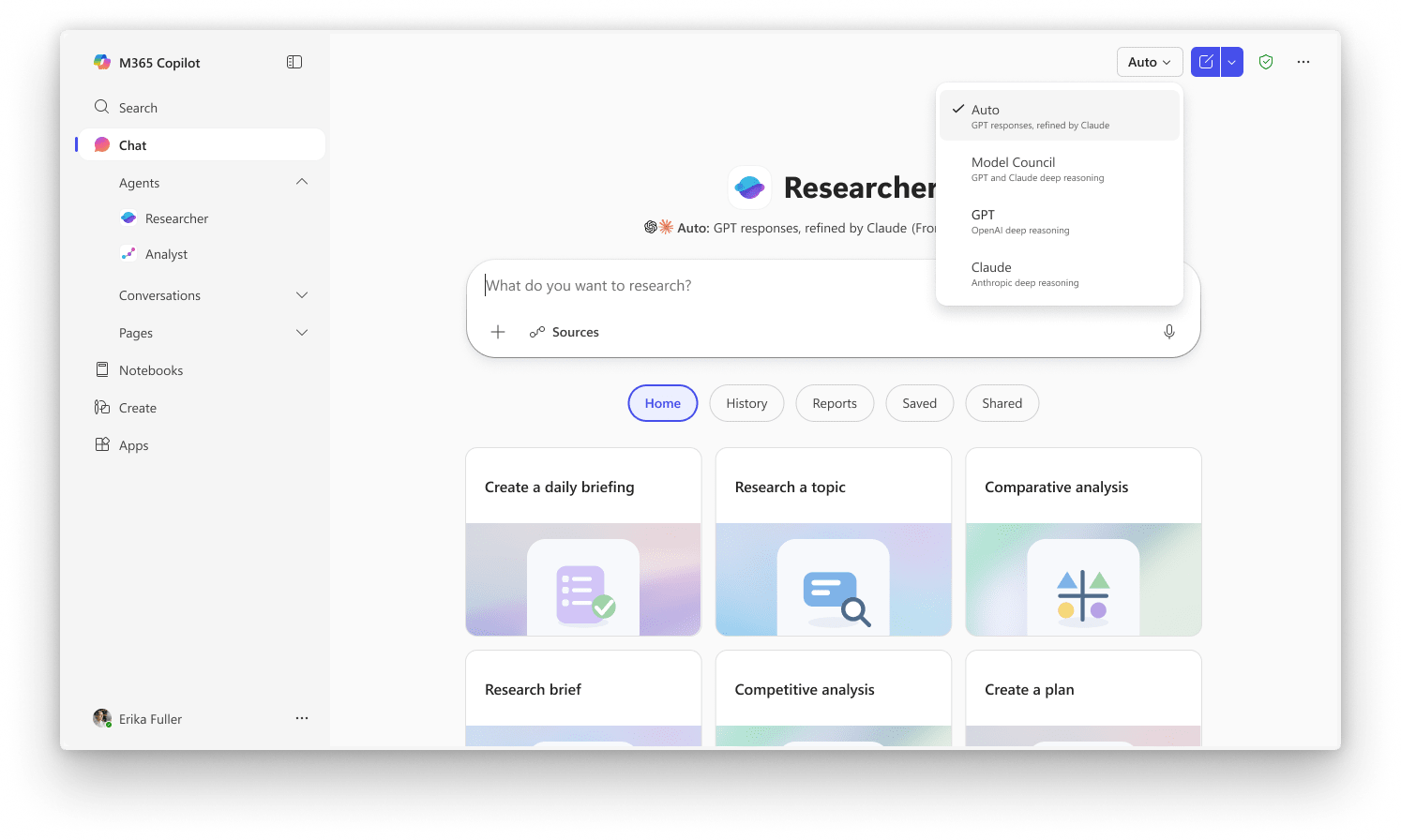
Enterprises chasing AI-driven transformation are learning a hard lesson: single-model intelligence isn’t enough for today’s complexity. Recent advances in multi-model AI—where multiple large language models (LLMs) collaborate, critique, and cross-validate—are redefining what’s possible in enterprise research, decision-making, and automation. Microsoft’s launch of Critique and Council within its Researcher agent for M365 Copilot signals a new era where model diversity equals higher accuracy, transparency, and trust. For technology leaders and developers, the message is clear: the future is multi-model, and the stakes are rising fast.
Why Multi-Model Intelligence Is Surging—And Why It Matters
Until recently, most AI research workflows in the enterprise relied on a single, general-purpose model to plan, retrieve, and synthesize information. But the limits of this approach are glaring when research tasks involve nuance, cross-domain knowledge, and the need for rigorous validation. Enter multi-model AI: architectures that assign specialized roles—such as generation, review, or domain-specific critique—to different models, creating a feedback loop that surfaces errors, fills analytical gaps, and elevates trustworthiness.
This shift isn’t theoretical. Gartner (2026) names multi-model AI and agentic systems as a top strategic technology trend, forecasting rapid adoption across industries. Their analysis predicts that by 2026, multi-model and agentic AI will become standard practice in enterprise software, with a growing emphasis on governance and domain specificity.
- Greater accuracy—models can check and refine each other
- Robustness—if one model misses a nuance, another can catch it
- Transparency—side-by-side outputs reveal not just what AI answers, but how and why
As organizations demand more evidence-grounded, trustworthy outputs from AI, these architectures are fast becoming essential, not optional.
How Microsoft Researcher’s Critique Changes the Game
Microsoft’s Critique system within the Researcher agent exemplifies this new paradigm. Instead of relying on a single LLM, Critique separates generation and evaluation—using one model (from Anthropic or OpenAI) to plan, retrieve, and synthesize, and a second, independent model to review, enforce evidence standards, and enhance the report. This mirrors academic peer review, but at machine scale and speed.
Results are dramatic: on the DRACO benchmark—a rigorous test encompassing 100 complex research tasks across 10 domains—Researcher with Critique scored 57.4, a +13.88% increase over the previous leader, Perplexity Deep Research (Claude Opus 4.6). The largest gains were in breadth and depth of analysis (+3.33), presentation quality (+3.04), and factual accuracy (+2.58), all statistically significant improvements (paired t-test, p < 0.0001).
Researcher with Critique achieves a substantial improvement of +7.0 points (SEM ±1.90) in the aggregated score, +13.88% over Perplexity Deep Research (Claude Opus 4.6 model), the best system reported in the paper. — Zhong et al., arXiv:2602.11685 (2026)
What makes Critique stand out is its rubric-based evaluation. The reviewer model focuses on:
- Source reliability: Prioritizing authoritative, domain-appropriate sources
- Report completeness: Ensuring comprehensive, intent-aligned answers
- Strict evidence grounding: Every key claim must be precisely cited
This approach doesn’t just catch mistakes—it proactively raises the bar on analysis, organization, and trustworthiness. For tech leaders seeking enterprise-grade AI, this is a watershed moment.

Council and the Power of Side-by-Side Model Comparison
While Critique separates generation and evaluation, Microsoft’s Council approach tackles another challenge: surfacing diverse perspectives by having multiple models independently analyze the same research question. With Council, Anthropic and OpenAI models each generate full reports, and a judge model distills where they agree, diverge, or contribute unique insights.
This is more than a technical feature—it’s a practical step toward greater transparency and explainability. By highlighting not just the final answer but the reasoning paths and disagreements between models, Council supports deeper trust and more informed decision-making for enterprise users.
In regulated industries, or when critical business decisions depend on AI-generated research, such side-by-side comparison can be invaluable. It empowers users to understand the range of possible interpretations, identify blind spots, and choose the most robust, well-evidenced conclusions.
- Consensus-building: Quickly spot where models align
- Risk mitigation: Recognize and investigate disagreements
- Analytical diversity: Leverage unique model strengths
For organizations looking to operationalize AI responsibly, Council demonstrates how model pluralism can move us beyond the “black box.”
Enterprise Impact: From Research to Real-World Transformation
The real test for multi-model AI isn’t in benchmarks, but in enterprise adoption and outcomes. Microsoft reports over 1,000 organizations using Copilot and Researcher to drive transformation, with case studies revealing significant time savings and quality gains across sectors (Microsoft, 2025).
Take the UK, where Blucando highlights 15 proven Copilot use cases ranging from legal research to healthcare, each demonstrating weekly productivity gains. These aren’t isolated stories: Gartner (2025) forecasts that by 2026, 40% of enterprise applications will feature task-specific AI agents, up from less than 5% in 2025.
However, challenges persist. Deloitte (2025) points to organizational barriers—governance, compliance, workforce readiness—as key hurdles to broader adoption. And as a 2026 study in Nature reveals, AI and humans can evaluate the same outputs very differently, underscoring the need for multi-metric, context-aware evaluation frameworks.
What’s clear is this: multi-model AI is rapidly moving from R&D to enterprise backbone, driving not just research quality but business outcomes.
Building for the Multi-Model Future: Practical Considerations
For developers and enterprise architects, embracing multi-model AI isn’t just about deploying more models—it’s about designing robust, orchestrated systems that maximize accuracy, transparency, and control. Key considerations include:
- Workflow orchestration: Seamlessly integrating generation, evaluation, and consensus steps
- Role specialization: Assigning models to tasks where they excel (e.g., synthesis vs. critique)
- Evaluation protocols: Adopting rubric-based, multi-metric frameworks to assess quality
- Governance and compliance: Ensuring explainability, auditability, and adherence to regulatory standards
At Jina Code Systems, we see multi-model architectures as the foundation for enterprise-grade AI agents—from research to automation and beyond. Our experience building AI-powered platforms for global clients shows that the real differentiator is not just smarter models, but smarter system design.
Success in this new era will require deep expertise in:
- Model selection and role assignment
- Orchestration of feedback loops
- Continuous benchmarking and improvement
- Alignment with evolving compliance frameworks
Organizations ready to lead must invest in not just AI, but in the engineering rigor that multi-model systems demand.
Conclusion
The multi-model AI revolution isn’t waiting for anyone. As Microsoft’s Critique and Council prove, the path to higher accuracy, trust, and enterprise value lies in orchestrating diverse, specialized models that challenge, refine, and explain each other’s work. For technology leaders, the imperative is clear: design for transparency, accountability, and continuous improvement—because the future of intelligent research and automation will be built on systemic intelligence, not just model intelligence.
Ready to architect your own multi-model AI solutions? Jina Code Systems is helping enterprises worldwide design, build, and scale agentic systems that deliver on the promise of next-generation AI. The bar is rising—let’s raise it together.